
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- cors
- 릿코드
- RT scheduling
- 타입스크립트
- 프로세스
- 이진탐색
- vue3
- 배열
- pytorch
- 컨테이너
- 연결 리스트
- 연결리스트
- 큐
- 브라우저
- Machine Learning
- 알고리즘
- GraphQL
- alexnet
- C
- 프론트엔드
- 자료구조
- 코딩테스트
- RxJS
- APOLLO
- 웹팩
- 자바스크립트
- 스택
- 포인터
- 해시테이블
- 프로그래머스
- Today
- Total
프린세스 다이어리
[Review] A new hybrid approach on WCET analysis for real-time systems using machine learning(2018) 논문 요약 리뷰 본문
[Review] A new hybrid approach on WCET analysis for real-time systems using machine learning(2018) 논문 요약 리뷰
개발공주 2023. 8. 28. 12:08T. Huybrechts, S. Mercelis, and P. Hellinckx, “A new hybrid approach on WCET analysis for real-time systems using machine learning,” in Proc. 18th Int. Workshop Worst-Case Execution Time Anal. (WCET), 2018, pp. 1–12.
(1) 연구의 필요성
Worst-Case Execution Time (WCET) of code는 Real-Time 시스템 개발 시 반드시 필요한 정보다. 개발 초기부터 WCET를 추정함으로써 pessimistic한 WCET 추정을 막고 과한 hardware 스펙을 방지해야 한다. WCET 분석을 위한 방법 중 hybrid 방법론에 ML을 결합할 것이다.
COBRA 툴은 실제와 근접한 WCET 값을 측정해 주지만, 여전히 타깃 하드웨어에서 코드를 컴파일해서 돌려야 한다는 단점이 있다. 개발 프로세스 초기에 코드가 없을 때, 프로젝트 사양 available system attributes(algorithms, code instructions, hardware model 등)이 정해진 시점에서 WCET 값을 추정할 수 있어야 한다.
Bonenfant은 특정 target plaform 및 compiler tool chain에 대한 공식을 얻기 위한 ML모델을 제안했다. 코드를 static하게 분석하여 worst case event의 갯수로 프로그램을 characterize 했다. 그러나 이렇게 이벤트 수만 고려하는 건 code flow 정보가 너무 손실되어 oversimplification의 문제가 있다. 소스코드를 로우레벨(hybrid blocks)로 나눠 모델을 학습시킴으로써 이러한 문제를 방지하고 정확한 WCET를 추정할 수 있다.
요약 - 개발 후에 피해보지 않게 개발 초기부터 WCET를 추정할 수 있어야 한다. Hybrid 방식으로 최소한의 코드와 system attribute를 가지고 ML 모델을 학습시켜 WCET를 추정하는 방법을 제시하겠다.
(2) Method
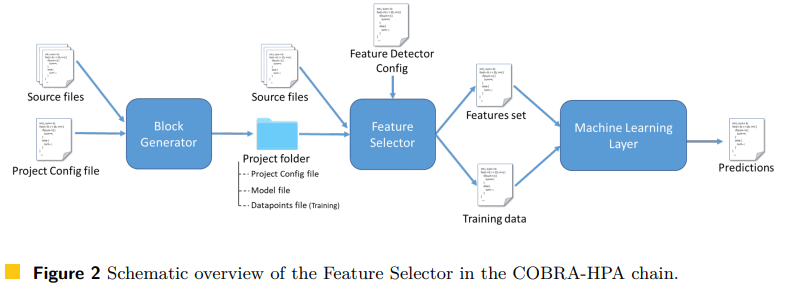
https://cobra.idlab.uantwerpen.be/
(1) 소스 코드를 Hybrid Block Generator를 활용하여 hybrid block으로 만들고, 이 block을 통해 attribute value set를 얻는다. (2) Feature Selector 모듈을 사용하여 hybrid blocks에서 나온 모든 feature를 formatted output file(XML)로 만든다. 이 과정에서 attribute가 선택되고 블록 내의 코드의 feature가 추상화되는데 이는 ML 학습을 덜 복잡하게 만드는 데 도움을 준다. (3) XML파일은 ANTLR v4로 파싱되어 csv 파일로 export 되고 이 데이터셋으로 다양한 ML 방법론을 훈련시킨다.
요약 - Input: features extracted from hybrid blocks, Output: WCET value
(3) Evaluation


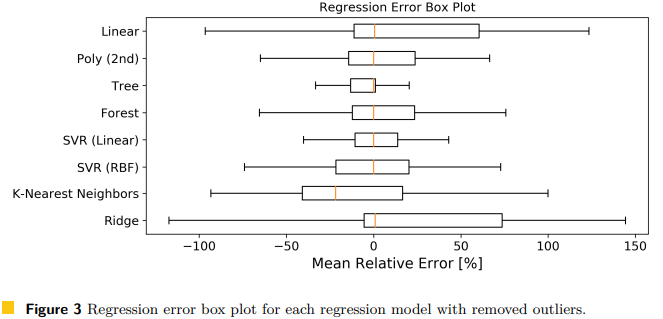

Dataset: Table1의 속성들은 Feature Selector 도구에서 모델링된다. TACLeBench benchmark 코드에서 뽑은 hybrid block으로부터 feature를 구축했다. Training data가 더 많이 필요해지지 않도록 반복문은 펼치는 등 feature의 수를 줄였다. Training set는 75개, verification set는 25개의 블록이고 4-fold 교차검증으로 반복된다. 각 블록은 Table 1의 모든 attribute와 WCET 값으로 주석이 달렸다.
Setting: (1) Environment: ARM Cortex-M3 CPU on the EZR32 Leopard Gecko board of Silicon Labs, (2) Model: Table 2의 기본 Regression model 사용, 모든 모델은 Scikit-Learn으로 구현, hyperparameter 조정 안함(ML을 이용하여 WCET를 예측할 수 있는지 가능성 조사를 위함), (3) Evaluation: Block size에 따라 error의 심각성을 다르게 평가하기 위해 Mean Relative Error 사용
Result: Support Vector Regression (SVR) with a linear kernel 사용했을 때 결과가 가장 좋았고, Tree와 KNN Regression이 그 다음이었다. 그러나 "Recursion" 벤치마크에 대해서는 Tree, KNN의 성능이 나쁘게 나왔다. 재귀적으로 호출되면서 작은 오차가 점점 커지기 때문이다.
요약 - 다양한 Regression model을 학습시켰고 평가에는 Mean Relative Error를 사용했다. 결과적으로 SVR with a linear kernel을 사용했을 때의 상대에러가 가장 작았다.
(4) Limitation, Future Work
Limitation: (1) 단일 코어, 캐시가 없는 "단순한" 아키텍처의 경우 SVR (Linear Kernel) 모델에서 높은 성능이 나오고 모델이 복잡해지면 overfitting될 것이다. 그런데 SVR 모델과 Tree 모델에서 좋은 결과가 나오긴 했지만 값이 discrete하다는 단점이 있다. 정확한 WCET 추정을 위해서는 data space를 더 분할해야 하고 이로 인해 복잡한 트리가 생성될 수 있다. (2) Hybrid block으로부터 WCET를 추정하는 것에 대한 가능성은 보여주었으나 attribute와 model의 튜닝을 통해 정확도를 더 향상시킬 것이고 이를 위해 더 많은 labeled data가 필요하다.
Future Work: 이 접근법이 초기 단계의 WCET 예측의 해결책이 될 것이라고 생각한다. 따라서 우리는 feature engineering에 중점을 둔 regression model을 개선하고, prediction model을 튜닝하고, 더 많은 데이터를 획득하고, DNN 및 ensemble models로 모델을 확장하고, 하드웨어/툴체인 관련 특징을 통합하여 계속 연구할 것이다
요약 - Single core, no caches 등 단순한 아키텍쳐에서 SVR (Linear Kernel) 모델이 WCET 추정에 유의미한 결과를 보였다. 추후 더 많은 데이터셋을 확보하고 ML 모델을 확장해야 할 것이고, 이번에는 SW만 고려했으니 다음에는 HW/toolchain 관련 attribute도 추가하여 연구하겠다.
(5) Comment
(1) 위 ML 기반 접근 방식은 측정 기반 접근 방식의 단점을 제거하지만 ML 모델은 시스템 아키텍처의 완벽한 타이밍 모델을 보장하지 않음.
(2) 소스코드 없이 개발전 프로젝트 사양만 정해지면 WCET를 진단할 수 있다는 게 믿을 수 있는 추정 값인지 의문
(3) HW 관련 attribute가 포함되지 않음
(4) 굉장히 제한적인 조건에서만 유의미함



