
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- GraphQL
- C
- 프론트엔드
- 프로그래머스
- 연결리스트
- 릿코드
- vue3
- 자바스크립트
- 이진탐색
- RxJS
- cors
- 스택
- RT scheduling
- 컨테이너
- 배열
- alexnet
- 코딩테스트
- 포인터
- 연결 리스트
- APOLLO
- 알고리즘
- 웹팩
- 자료구조
- Machine Learning
- 큐
- pytorch
- 프로세스
- 해시테이블
- 브라우저
- 타입스크립트
- Today
- Total
프린세스 다이어리
[Review] Pruning Meets Low-Rank Parameter-efficient Fine-tuning 논문 정리 본문
[Review] Pruning Meets Low-Rank Parameter-efficient Fine-tuning 논문 정리
개발공주 2023. 9. 22. 16:16Zhang, Mingyang, et al. "Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning." arXiv preprint arXiv:2305.18403 (2023).
요즘 관심 있는 pruning, PEFT 관련하여 재미있는 논문이 있어 정리해 보았다. 이 리뷰글은 논문 내용만을 담고 있지는 않는다.
1. 연구의 필요성
(1) Problem Statements
LLaMA와 ViT-G 같은 Large pre-trained model은 다양한 task에서 성능이 높다. 파라미터가 많을 수록 다양한 task에서도 성능이 높아진다는 공식은 아직까지 유효한 것으로 보인다. 그런데 모델 사이즈와 연산 비용 때문에 성능이 제한된 모바일 디바이스 등에 배포가 어렵다는 단점이 있다. 한편, LPM의 경우에 task를 수행하기 위해 fine-tuning 과정이 필요한데, 사전 training 된 weight를 건드리지 않는 효율적인 방법으로 fine-tuning 하는 다양한 방법론을 적용할 수 있다.
또, 거대 모델을 모바일 디바이스 등에 배포하기 위해 사용하는 model compression 기법 중, pruning이 대표적인 기법 중에 하나다. Parameter의 중요도를 평가해서, redundant parameters를 삭제함으로써 모델 성능은 거의 유지하면서 사이즈를 줄인다. 그런데 LPM을 효율적인 방법으로 fine-tuning 하는 다양한 방법론을 적용하려면 굳이 기존 모델의 전체 gradient를 계산하지 않아도 되는데 pruning하기 위해 전부 접근해서 계산해야 하는 것이 연산 및 메모리 부담이 된다.
(2) 해결방안
그래서 논문은 LoRA로 유명한 low-rank adaptation 기법과 pruning을 결합한 LoRAPrune을 제안한다. LoRAPrune을 구현 할 수 있는 방법을 수식적으로 증명하고, 이 방법을 활용하였을 때 성능은 어떠한 변화가 있는지 얼마나 efficient 한지 보여준다.

먼저 LoRA라는 건, large pre-trained model의 파라미터를 효율적으로 fine-tuning하는 PEFT 기법 중 하나다. 그냥 pre-trained weight를 전부 다시 학습해서 fine-tuning을 하는 거랑, parameter-efficient한 방법으로 fine-tuning 하는 거랑(PEFT) 연산량과 메모리 효율성 측면에서 큰 차이가 난다. 그 PEFT 기법 중 하나로 LoRA라는 방법이 기존에 제안되었다. LoRA는 pre-trained weight은 그대로 freeze하고, 작은 사이즈의 module 하나를 필요한 레이어에 추가해서 이 모듈만 계속 학습하고 업데이트해서 fine-tuning을 하는 방법이다. LoRA 논문을 처음 접했을 때 꽤 흥미로웠던 기억이 난다.
다음으로 pruning은 대규모 모델에서 중요치 않은 파라미터를 제거해서 메모리나 연산량을 줄이는 대표적인 model compression 기법이다. 즉 기본적인 pruning 방법으로는 그 파라미터가 중요한지 여부를 가리기 위해서는 전체 파라미터를 다 접근해야 한다는 것이다. 이런 경우 LoRA를 함께 적용할 수 없게 된다. Pre-trained weight을 접근할 필요 없도록 그대로 고정해 두고, 작은 사이즈의 모듈만 학습하고 업데이트하는 게 LoRA를 포함한 PEFT의 메인 아이디어이기 때문이다. 그래서 저자는 LoRA를 유지하는 동시에 pruning하여 모델 사이즈까지 줄일 수 있을지 해결할 수 있는 LoRAPrune이라는 방법을 제안한다.
2. Method
LoRA는 PEFT 방법의 선두주자로, fine-tuning 시 low-rank를 가진 adapter A, B를 가지고도 fine-tuning 성능을 유지하는 방법이다. Fine-tuning하고자 하는 weight가 d x k 사이즈라고 한다면, low-rank matrices A, B는 각각 rank r로 축소되어 d x r, r x k로 나타낼 수 있다. LoRA는 과도하게 parameterized 모델이 본질적으로 낮은 고유 차원을 차지하기 때문에 아주 낮은 rank(GPT-3 175B를 예로 들면 전체 랭크가 12,288만큼 높더라도 랭크는 1, 2여도 충분함) 만으로도 완전히 훈련된 모델과 같거나 더 나은 성능을 보일 수 있다고 한다. 복잡도가 높은 데이터를 주성분분석을 해서 dimension을 줄이는 것이랑 비슷한 맥락으로 이해하였다.

이러한 LoRA와 pruning을 합칠 때는 특정한 방법이 필요하다. Pruning을 하려면 gradient를 전부 계산해서(이 논문에서는 parameter의 중요도를 weight의 크기가 아닌 gradient 기반으로 판단하는 방법을 채택한다) 덜 중요한 것을 삭제해야 하는데, 그러면 LoRA 방식을 활용하여 pre-trained weight을 최대한 안 건드리려고 한 노력이 헛되게 된다. 그래서 LoRAPrune은 low-rank 어댑터의 gradient만 계산해서, pre-trained model의 gradient를 추정함으로써 삭제할 parameter를 판단한다. LPM의 gradient 계산, 메모리 저장 없이 작은 모듈만을 가지고도 pruning의 대상을 추정할 수 있다는 것이다.
(1) Parameter importance
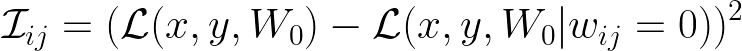
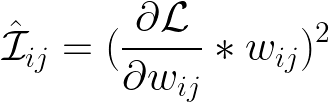
$\mathcal{I_{ij}}$은 importance다. 그러니까 pre-trianed paramter의 각 중요도를 뜻한다. 이 중요도는 기본적으로 원래의 weight 값으로 도출한 loss와, 그 해당 parameter를 0으로 두고 도출한 loss값의 차이를 가지고 판단한다. 당연히 이 차이가 클 수록 해당 파라미터가 모델의 성능에 중요하다는 의미다. 그런데 이 방법은 모든 파라미터들의 조합에 대해 loss를 계산해야 하기 때문에, large pre-trained model에는 적합하지 않다. 그래서 테일러 전개법으로 근사한 게 $\mathcal{\hat I_{ij}}$ 이다. 그런데 이렇게 근사를 해도 결국 gradient를 하나하나 계산해야 하는 것은 변하지 않는다.
그래서 저자는 low-rank matrices인 A, B를 가지고 중요도를 추정할 수 있다는 것을 입증한다. PEFT를 위한 adapter를 parallel하게 추가하는 방법과, sequential하게 추가하는 방법이 있다. 둘 다 A, B의 gradient를 각각 구한다는 건 같은데, 다 학습하고 나서 기존의 weight에 어떻게 reparameterization 되어 합쳐지는지에 약간 차이가 있다. 그래서 저자는 두 케이스로 나누어서 설명을 하는데 사실 수식을 하나하나 뜯어서 이해하는 것도 크게 어렵지는 않지만 어떻게 A, B의 gradient로 pre-trained gradient의 중요도를 추정할 수 있는지에 대한 증명 내용이라 핵심만 정리하기로 했다.
a. Parallel low-rank adaptation
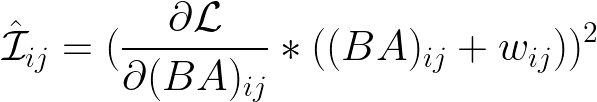
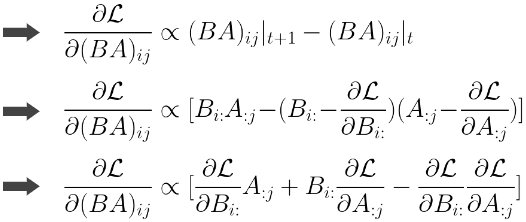
위는 parallel low-rank adaptation 케이스에서의 importance score 근사 값이다. Adaptation 이후 re-parameterization까지 한 다음 원래의 weight에 합쳤을 때 W=W_0+BA가 된다. 이제 이걸 low-rank A, B의 각 gradient만 계산하기 위해서는 저 식을 나눠야 한다. (1) 먼저 t+1번째 BA_{ij} 값과 t번째 BA_{ij} 값은 learning rate이 곱해진 gradient값 만큼 차이가 난다. 그럼 이 gradient 값은 t+1번째 값에서 t번째 값을 뺀 값에 비례할 것이다. (2) B의 i번째 행, A의 j번째 열에 대한 gradient로 분리를 한다. (3) 마지막으로 한 번 정리해 준다. 각 pre-trained parameter가 low-rank gradient 값과 비례하기 때문에 중요도 점수를 추정할 수 있다는 내용이다.
b. Sequential low-rank adaptation
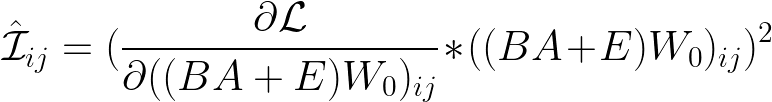
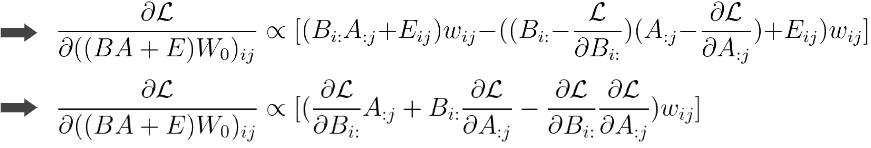
위는 sequential low-rank adaptation 케이스에서의 importance score 근사 값이다. 전개를 해 보면 마찬가지로, 전체 gradient 값을 A에 대한 gradient와 B에 대한 gradient 값으로 분리해서 parameter importance를 추정할 수 있게 된다. 따라서 이렇게 추정하게 되면, pruning을 할 때 모든 pre-trained model의 파라미터의 gradient를 구하지 않아도 그 작은 사이즈만 구해도 되고 즉 메모리와 연산량이 경감된다.
(2) Utilizing moving average
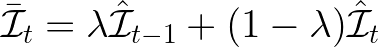
처음에는 pre-trained model의 W는 잘 train되어 있고, adapter의 파라미터는 제대로 최적화되지 않은 상태일 것이다. 이 상태에서 모든 파라미터를 최적화한 후, 반복적으로 중요하지 않은 파라미터를 pruning 할 수 있겠지만 이는 시간 비효율적이다. 따라서 각 pruning 반복마다 이동 평균을 사용하여 파라미터의 중요도를 평가하면서 fine-tuning을 하는 편이 효율적이다. 각 파라미터의 중요도를 추정하는 방법을 알았으니, $\mathcal{\hat I_{t-1}}$ 값과 $\mathcal{\hat I_t}$ 즉 t-1번째와 t번째 값을 추정할 수 있게 된다. 이걸 가지고 매 반복 시 moving average, 이동 평균을 계산할 수 있다. λ ∈ [0, 1]는 과거와 현재 값 사이의 중요도를 조절한다.
(3) Forward process with pruning mask
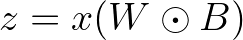
파라미터에 대한 binary mask $B ∈ \{0, 1\}^{d×k}$를 삽입하고 나서 ‘prune-finetune-prune’ 방법으로 pruning을 한다
Parameter importance가 주어지면, 각 pruning iteration 동안 sparcity ratio에 따라 상위 k개의 파라미터만 해당 마스크를 1로 설정하고 나머지는 0으로 설정한다. 각 레이어의 forward process는 (1) 각 pruning 반복마다 LoRAPrune은 위 식으로 forward, backward propagation을 수행하고 low-rank adaption을 업데이트한다. (2) 현재의 중요도 점수를 importance function을 이용하여 계산한다. (3) 이전 중요도 점수와 다음 중요도 점수를 활용해 moving average 중요도 점수를 계산한다. (4) 이진 마스크에 남아 있는 파라미터의 수가 sparcity 비율보다 많으면 알고리즘은 이진 마스크의 상위 k개의 중요하지 않은 파라미터를 추가적으로 제거하여 sparcity ratio를 맞춘다.
3. Evaluation
(1) Dataset
데이터셋은 다양한 태스크에 적용해 보기 위해 VTB-1k, FGVC, GLUE 벤치마크로 진행을 하였다. 32개의 Computer Vision, Natural Languate Processing task를 수행하였다.
CV task의 경우, pre-trained model은 ViT/16 backbone에 세 가지의 pre-training methods (supervised pre-training, and self-supervised pre-training with MAE and MoCov3)를 적용하였다. Fine-tuning strategies로는 Sensitivity-aware visual parameter-efficient tuning을 활용하였다.
NLP task는 pre-trained model로 BERT를 사용하였다고 한다. 공통 설정으론 한 개의 RTX 3090 GPU로 돌렸고 pruning 대상은 Attention 레이어의 FC layers와 Feed Forward Network라고 한다.
(2) Results
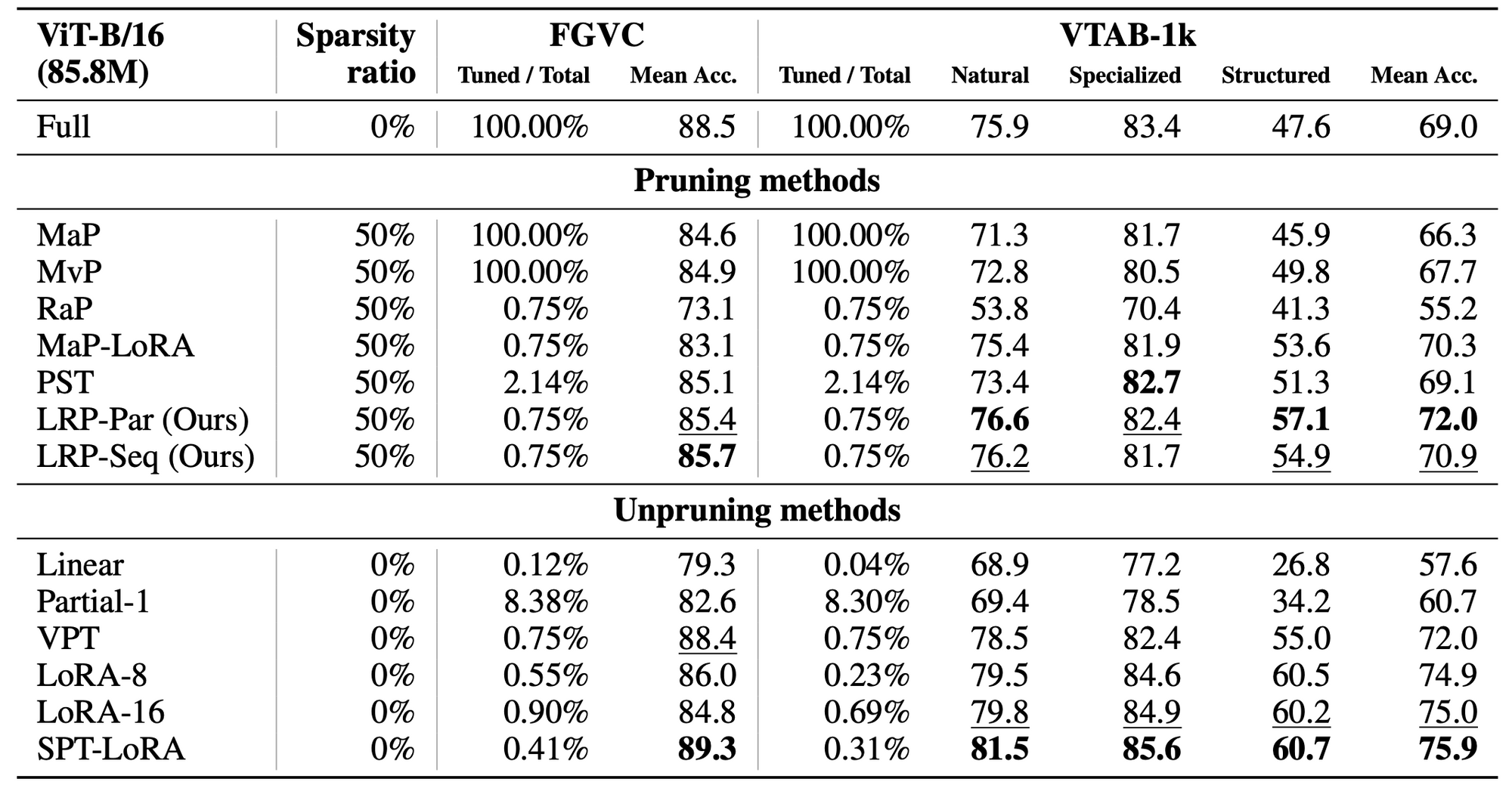
- Image classification task에서, FGVC와 VTAB-1k benchmark에서 다양한 pruning 방법을 사용하여 비교한 결과,
- Original parameter gradients를 사용하여 pruning을 하는 MvP 방식보다 4.3% 높다
- Pruning 안 하는 fine-tuning 결과와 비교했을 때도 LoRAPrune이 좋은 결과가 나왔다
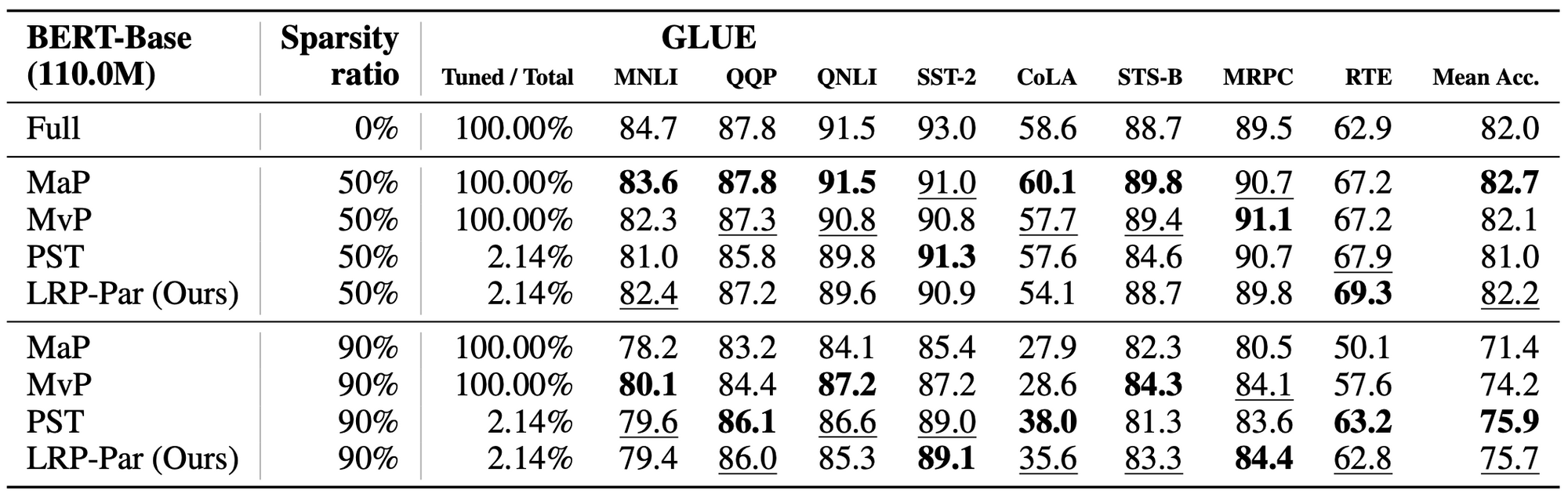
- Natural language understanding task에서 GLUE 데이터셋으로 실험한 결과,
- Full fine-tuning 방법들과 비교해서, LRP-Par는 2.14% 파라미터만을 가지고 fine-tuning 했고 견줄 만한 성능을 보인다
- Sparsity ratio가 50%인 경우 평균 스코어 개선이 좀 더 있었다
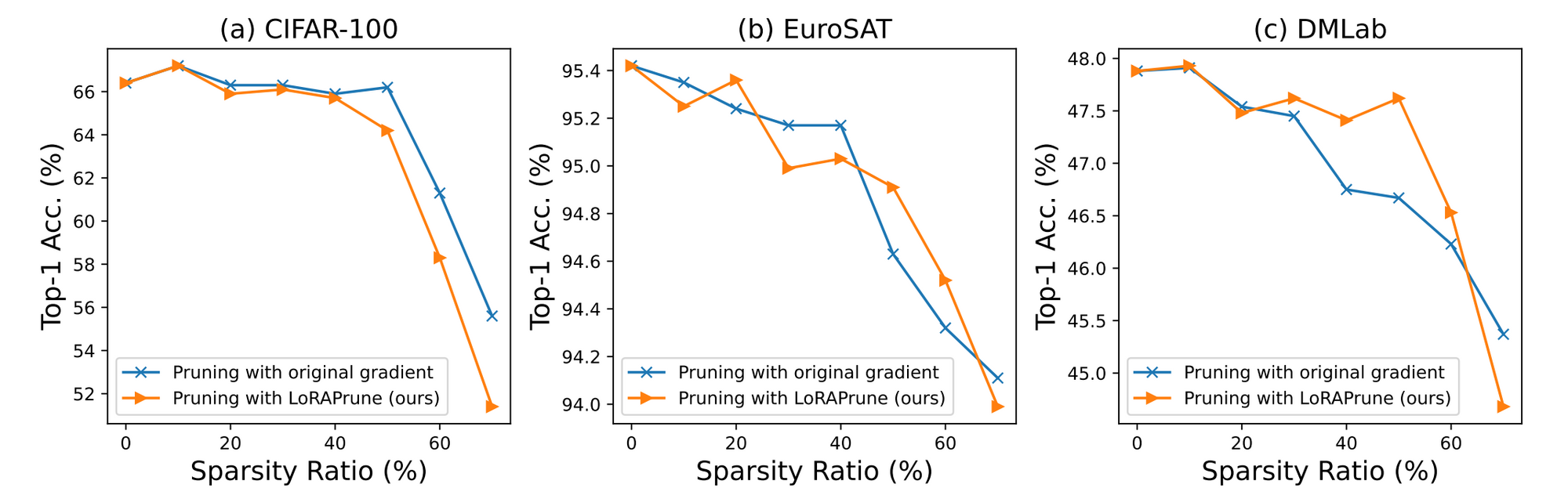
- 논문에서는 low-rank matrices의 gradients를 활용하여 original parameter의 gradient를 추정하는 방법을 제안하며, 만일 original parameter의 gradient를 그대로 사용하면 어떤 결과가 나타날지 실험한 결과,
- CIFAR-100(Natural), EuroSAT(Specialized), and DMLab(Structured) datasets 각각의 데이터셋 및 여러 sparsity ratio 조건에서 모두 comparable하거나 더 나은 성능을 보이고 있다
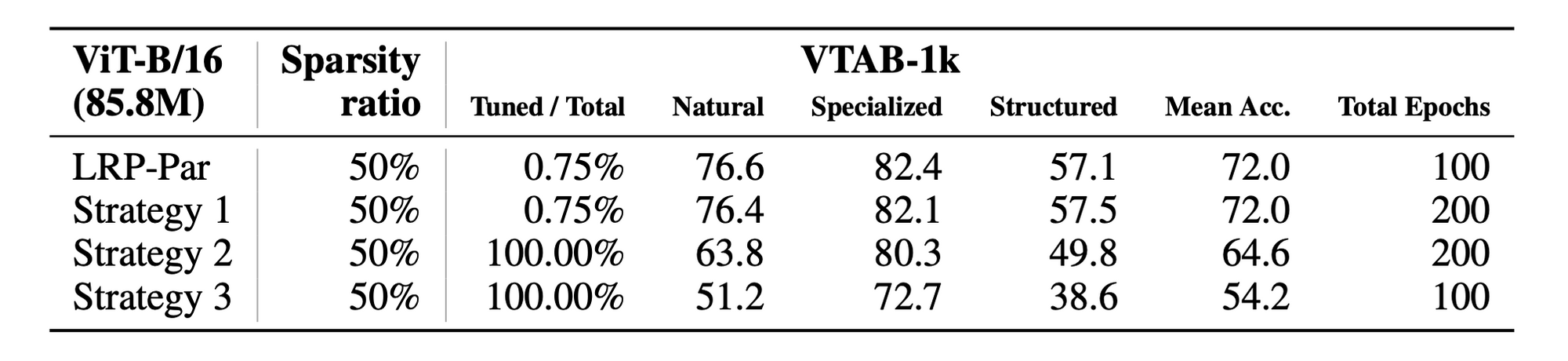
- LoRAPrune은 fine-tuning 과 pruning을 동시에 진행하는데, 만약 fine-tuning과 pruning을 따로 떼었을 때는 어떤 결과가 나타날지 실험하기 위해,
- 이미 준비된 well-adapted model을 (1) 논문에서 제시한 fine-tuning LoRA 방법 대로 점진적인 pruning 하고, (2) Original gradient를 점진적으로 pruning 하고 모든 파라미터를 fine-tuning하고, (3) Optimal brain surgeon 방법에 따라, 일괄적으로 one-shot pruning을 하고 남은 parameter를 재구성하였다
- 그 결과 점진적인 pruning이 성능에 좋은 영향을 미치며 Pre-trained Language Model의 성능에 영향을 미치지 않는다
4. Conclusion
이 논문은 (1) 파라미터의 중요도를 low-rank matrices만을 가지고 계산할 수 있는 새로운 접근법을 제안한다. 이 접근법은 대규모 모델의 pruning에 필요한 연산량을 크게 감소시킨다. (2) 이 접근법을 기반으로, LoRAPrune 이라는 pre-trained weights의 gradients를 계산하지 않고도 pruning과 fine-tuning이 가능한 기법을 제안한다. (3) CV와 NLP 태스크를 대상으로 종합적인 실험을 하였고, 이를 통해 모든 parameter의 gradients를 계산해야 하는 다른 pruning 방법들과 비교하여 성능이 뛰어남을 보여준다. (4) Ablation study를 통해 LoRA gradients를 사용하여 파라미터의 중요도를 검사하는 것이 더 효율적이고 정확하다는 것을 밝혀냈다.
Limitation으로는 (1) Pruning process에서는 GPU memory가 많이 소요되지만, 학습과 추론 과정에서 효율성을 높였기 때문에 장기적으로 에너지소비 및 탄소배출량을 절감할 수 있다 (2) 악의적인 공격에 의해 수정될 위험성이 존재한다. (3) Hardware-software codesign을 한 건 아니고, 알고리즘 레벨에서만 효율성을 보여준다는 점을 짚었다. Future work에서는 LoRAPrune을 ViT-G, LLaMa-7B와 같이 더 많은 파라미터를 가진 더 큰 모델에 적용해 볼 것이라고 한다.



