
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Machine Learning
- 연결리스트
- 이진탐색
- cors
- 포인터
- 타입스크립트
- 알고리즘
- vue3
- 큐
- 컨테이너
- APOLLO
- C
- 프로세스
- 웹팩
- 릿코드
- RxJS
- alexnet
- 브라우저
- GraphQL
- 코딩테스트
- 스택
- 연결 리스트
- 해시테이블
- 프론트엔드
- 배열
- 자바스크립트
- 자료구조
- RT scheduling
- pytorch
- 프로그래머스
- Today
- Total
프린세스 다이어리
[Review] Workflow scheduling using neural networks and reinforcement learning 논문 리뷰 및 요약 본문
[Review] Workflow scheduling using neural networks and reinforcement learning 논문 리뷰 및 요약
개발공주 2023. 8. 29. 11:13Melnik, Mikhail, and Denis Nasonov. "Workflow scheduling using neural networks and reinforcement learning." Procedia computer science 156 (2019): 29-36.
1. 연구의 필요성
컴퓨팅 시스템 최적화를 위해 scheduling이 필요하다. 효과적으로 scheduling 문제를 해결하기 위해선 계산 모델과 resource의 높은 heterogeneity 등 다양한 컴퓨팅 환경에 적응하고 학습할 수 있어야 한다. 아직 ML은 scheduling 문제를 해결하기엔 충분치 않다.
기존의 RL을 활용한 scheduling 연구는 (1) 외부 Grid 자원에 따라 task distribution하는 것을 목표로 하는 연구, (2) MapReduce planning 연구, (3) Cloud environment 의 planning 연구 등이 있는데, task 수, resource 수 등 아주 기본적인 정보 만을 고려하고 있고, NN 모델을 사용하지 않는다.
저자의 연구와 관련된 연구는 (1) RL 기반, 모든 task가 비슷한 execution time을 가지고 서로 종속적인 계산 자원을 고려한 scheduling 체계를 제안한 연구, (2) 포인터 네트워크를 기반으로 한 RL scheduling 알고리즘 개발 등이 있다. 이와 달리 우리는 workflow의 구조에 따른 input state와 possible actions를 고려한 더욱 종합적인 scheduling 문제를 다룰 것이다.
요약: scheduling 문제를 해결하기 위해 ANN, RL 및 workflow structure 분석을 기반으로 한 scheduling 체계를 제안한다.
(2) Methods
Workflow scheduling problem
💡 Workload is presented as a directed acyclic graph (DAG) $W f = < T, E >$ where..
- $T = \{t_i\}$ is a set of tasks and $ E = \{e_{j,k}\} $ is a set of edges ($t_j $ is parent pred(t) and $ t_k $ is child succ(t))
- $N = \{n_i\}$ each computing nodes is physical or virtual computing resource ( $n_i$ = CPU core, RAM, ..attr), that are connected via set of bandwidths $B = \{b_i\}$
- $S = \{(t_i, n_j)\}$ Schedule is an ordered assignment of tasks to resources
Workload 내에 여러 workflow가 존재할 수 있다. Scheduling 문제 분야에는 다양한 기준(작업 시간 makespan, cost, reliability)과 제약 조건(deadline, budget)이 있지만 이 연구에서는 workflow의 총 실행 시간 total execution time of workflow만으로 최적화를 수행한다.
💡 Finding the optimal workflow schedule $S_{opt}$
- Task makespan = task execution time $ET(t, n)$ + data transfer time from parent task to child task $TT(t_i, t_j) = e_{i, j}/b_k$
- Full execution time = $FT(t, n) = max_{t_i∈pred(t)}(TT(t_i, t)) + ET(t, n)$
- Actual finish time of task = $AFT(t)$ which takes into account all dependencies and queues in the schedule
- workflow total execution time is defined as a finish time of last executed task makespan = $max_{t_i∈T}(AFT(t_i))$
- $S_{opt}$ is the optimal schedule that will minimize makespan of workflow. </aside>
Task의 전체 작업 시간 FT는 task 실행 시간과 task 간 데이터 전송 시간을 더한 값이다. Task의 실제 종료 시간 AFT는 스케줄 내의 모든 의존성과 큐를 고려하여 task가 완료되는 시점이다. 논문의 목적인 workflow scheduling은 makespan 이 최소가 되는 최적의 스케줄을 찾는 것이다.
Reinforcement learning
💡 Agent(scheduling algorithm) vs External environment(computing environment)
- $a_i$ from the set of possible actions $A$ under the current state $s$ from the state space $S$
- $Q_t(s_t, a)$ is an evaluation function the agent enters a new state $s$ and receives a reward $r$ from the environment $r(s, a)$
- $a_t = argmax_aQ_t(s_t, a)$ is the action at time moment $t$
- $Q(s_t, a_t) ← Q(s_t, a_t) + α[r_t + γQ(s_{t+1}, a_{t+1}) − Q(s_t, a_t)]$ is the evaluation function that is updated according to the SARSA principle
- $α$ is learning rate(Q값 업데이트에 얼마나 많은 영향을 줄지) and $γ$ is a future actions importance factor(미래의 보상에 대한 현재의 가치)
- The approximation function $f(s, a)$ may be constructed for continuous state space
Agent(scheduling algorithm)은 environment(computing env)와 상호작용을 한다. Agent는 주어진 상태에서 가능한 최상의 행동을 선택하려고 시도한다. Agent가 행동을 취하면 SARSA 원칙에 따라 (State, Action, Reward, State', Action')이라는 tuple을 얻게 되고 이를 이용해 Q값(state와 action 쌍에 대한 가치 함수)을 업데이트한다.
Neural network scheduling algorithm


(1) NN의 input state s는 여러 computing resources 정보가 인코딩 된 vector parameter다. Output action a는 현재 시점의 task를 어느 노드에 할당할지, 예약해야 할지 결정하는 최적의 예측 값이다. (2) Computing environment는 NNS agent로부터 action 값을 받아 이를 토대로 specified resource에 task를 추가한다. (3) Task가 예약되면 computing environment가 현재 workflow execution time과, 그의 새로운 state *s'*를 평가하고 NNS agent를 위한 보상 r을 평가한다. (4) NNS agent는 받은 {s, a, r, s'} 순서를 vector 형태로 SARS 메모리에 저장한다. Input state가 terminate 할 때까지 계속 수행한다.
이 과정은 컴퓨팅 환경의 상태를 인코딩할 때 어떠한 parameter들을 사용할 것인지 결정하는 것에 집중하고 있다. Workflow들이 서로 다르기 때문에 다양한 형태의 workflow와 data를 dynamic scheduling 할 수 있어야 한다. 그래서 workflow의 최악의 시간 worst time of workflow’s execution $WT(W f)$ 을 정의한다. 이를 기준으로 다양한 매개변수를 상대적인 값으로 변환할 수 있고 따라서 알고리즘은 다양한 환경과 workflow에 유연하게 대응할 수 있다.

(1) Relative열은 이 매개변수들이 WT에 대한 상대적인 값인지 알려준다. (2) Use 열은 실험에서 어떤 매개변수가 사용되었는지 나타낸다. 사용되지 않은 매개변수들 없이도 알고리즘의 결과는 잘 나왔지만 앞으로는 추가할 예정이라고 한다. 현재 input state 에서는 relationship between tasks는 tr_data 매개변수에 의해 충분히 결정된다. 사용된 매개변수 집합으로 입력 상태 벡터의 차원은 5+n+3∗m+2∗n∗m으로 계산되며, 여기서 m은 task 수고 n은 NNS agent가 구축된 node 수다(5개의 작업과 4개의 노드를 갖는 아키텍처의 입력 벡터 크기는 64). Actions의 수는 n*m이다. Reward function은 다음과 같다.
$$ \displaystyle r(s, a) = \dfrac{ worst\_time } { current\_makespan } * \dfrac{ scheduled\_tasks }{n} $$
요약 - Neural Network Agent는 input으로 컴퓨팅 리소스의 부하, 작업량 등 컴퓨팅 소스 정보가 인코딩 된 벡터 파라미터를 받아, output으로 작업을 어느 노드에 할당할지 결정하는 action을 출력한다. Action 값에 따라 task scheduling이 이루어지고 나면, 새로운 state s’ 값과 reward r 값을 평가한다. 이는 input이 더 이상 없을 때까지 SARS 메모리에 {s, a, r, s’} 형태로 저장된다. 이것이 한 차례의 episode다.
3. Evaluation
Input Data: Workflows from Pegasus(contains workflow execution logs, input/output data size, tasks dependency)
Simulation setting: (1) Computing nodes: 4 computers, each has 4, 8, 8, 16 CPU cores, (2) Network Bandwidth: 10 MB/s, (3) Workflow size: Small workflow(5-10 tasks), medium workflow(25-30 tasks), (4) NN architecture: takes 5 tasks, 4 nodes, which forms 64 × 1024 × 512 × 256 × 20 full-connected network, ReLU, Adam, batch_size 128, update model each 10 episodes
Task execution time calculation: $ET(t, n) = \dfrac {t_{runtime}} {log(n_{capacity} + 1)}$
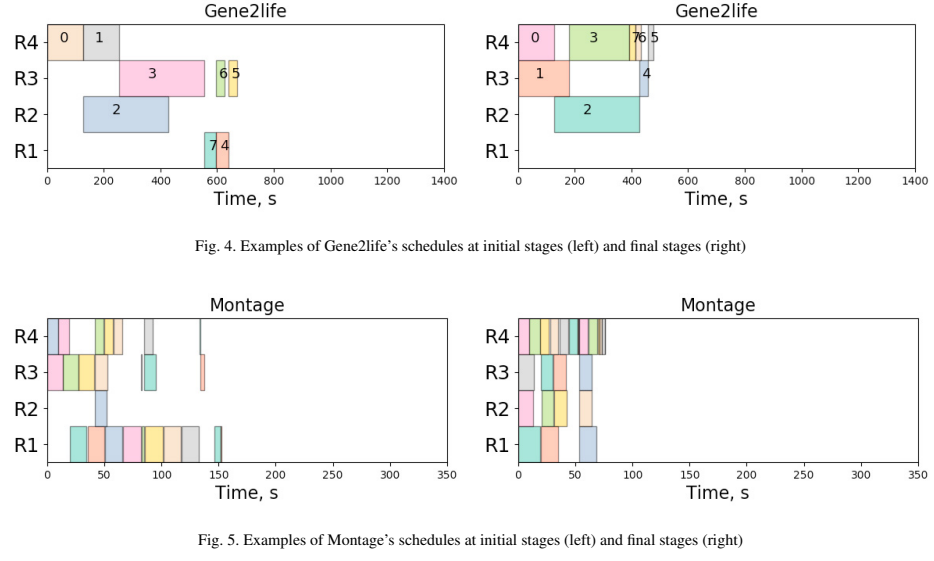
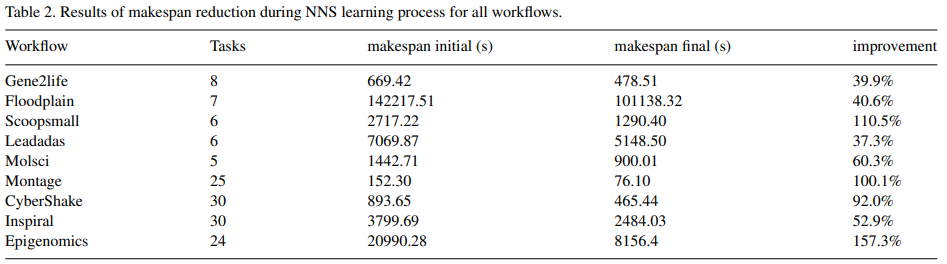
Results: (1) Small workflow set 학습 결과: 성능이 가장 뛰어난 R4 resource에 task를 배치하려고 시도했다. 병렬 작업이 존재하는 경우엔 평균 성능인 R2, R3에 병렬로 배치함. R4가 R2나 R3보다 28% 빠르게, 그리고 R1보다는 76% 빠르게 작업을 실행하더라도, 이 차이를 보상으로 인식하는 것은 알고리즘에게 쉽지 않았지만, 여전히 Gene2life의 작업 시간은 670초에서 480초로 39% 감소했다. (2) Medium workflow set 학습 결과: Small workflow set과 구조, 병렬 정도, 데이터 전송 시간 당 실행 시까지 달랐지만, episode를 거치며 Figure 5와 같이 execution time이 감소했다. 전반적으로 모든 workflow에서 평균 76.7%이 개선되었다.
요약 - Pegasus에서 workload input data를 얻었고, 다양한 사이즈의 컴퓨팅 리소스에 스케줄링하도록 학습시켰다. 그 결과 작은 뭐크플로우 세트와 중간 사이즈의 세트 모두 전반적으로 execution time이 감소하였다.
4. Limitation, Future Work
Limitation: 각 workflow의 이론적인 실행 시간에는 개선의 여지가 있다(The difference between workflows also lies in the possible improvement over the theoretical execution time). 이 차이로 인해 reward 값의 큰 분산이 발생하고 학습이 어려워진다.
Future works: (1) input state의 인코딩 방식을 더 상대적이고 적합한 parameter로 개선하려고 한다, (2) task order와 node execution 사이에 뚜렷한 연결 관계가 있다는 점에서 NN 모델 구조를 RNN 또는 LSTM으로 변경하려고 한다.
요약 - input state의 인코딩 방식을 개선할 것이고, task 순서와 실행의 전후관계를 고려하는 RNN 또는 LSTM으로 모델을 변경해 보겠다.



