
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 브라우저
- vue3
- 연결 리스트
- 큐
- 자바스크립트
- pytorch
- 연결리스트
- 웹팩
- 해시테이블
- RT scheduling
- 스택
- APOLLO
- 알고리즘
- 배열
- RxJS
- 컨테이너
- 포인터
- cors
- C
- GraphQL
- 자료구조
- Machine Learning
- 타입스크립트
- 프로그래머스
- 프론트엔드
- 코딩테스트
- 프로세스
- alexnet
- 이진탐색
- 릿코드
- Today
- Total
프린세스 다이어리
[Review] Towards Automatic Assessment of Perceived Walkability 논문정리, 리뷰 본문
[Review] Towards Automatic Assessment of Perceived Walkability 논문정리, 리뷰
개발공주 2023. 9. 23. 22:40Blečić, Ivan, Arnaldo Cecchini, and Giuseppe A. Trunfio. "Towards automatic assessment of perceived walkability." Computational Science and Its Applications–ICCSA 2018: 18th International Conference, Melbourne, VIC, Australia, July 2–5, 2018, Proceedings, Part III 18. Springer International Publishing, 2018.
https://link.springer.com/chapter/10.1007/978-3-319-95168-3_24
한줄요약: 인간이 인지하는 거리의 walkability를 pre-trained VGG16 model에 Google Street View images를 fine-tuning한 모델을 활용하여 분석하는 방법을 제안한다.
1. 연구의 필요성
보행자 중심의 도시를 계획하기 위해서는 보행자의 요구, 행동 및 인식 needs, behaviours and perceptions에 주의를 기울여야 한다. 보행자의 접근성 분석은 걷기 적합성을 평가하는 것을 중심으로 많이 이루어지고 있다. 걷기 적합성을 적절하게 평가하기 위해서는 보행자 인프라로 인한 연결성, 접근성 및 서비스 수준을 분석하는 것 외에도, 품질, 쾌적성, 편안함, 안정감 등에 대한 보행자의 주관적 인식을 함께 고려해야 한다. 주관적 인식을 평가하기 위해서는 현장에서 또는 화면상의 사진을 통해 직접 사람이 관찰하는 과정이 수반되는데 비용문제 때문에 조사 범위가 제한된다는 한계점이 있다. 따라서 이 연구에서는 (반)자동 절차를 제안한다. Google Street View의 데이터셋을 CNN으로 분석하는 방법을 적용하였다.
요약 - 보행자 중심의 도시를 계획하기 위해 접근성 분석이 필요하다. 접근성 분석을 위해, 객관적인 보행자 인프라 분석에 보행자의 주관적 인식에 대한 분석이 함께 진행되어야 한다. 이 연구에서는 주관적 인식 분석을 위한 자동화된 분석 방법을 제안한다.
2. Method
(1) Dataset

훈련된 평가자에게 Google Street View의 이미지들을 보여주고, 보행 가능성이 낮은 1부터 보행 가능성이 높은 5까지의 평가 척도를 사용하여 직접 평가하도록 하였다. 이미지 평가는 웹 인터페이스 상에서 이루어졌다. 클래스 1에 3,501개 이미지, 클래스 2에 3,038개, 클래스 3에 8,012개, 클래스 4에 1,700개, 클래스 5에 나머지 952개 등 채택된 5개 클래스로 분할되었다.
- 17,203 dataset → training set 70%, validation set 10%, test set 20%로 랜덤 분할
- training set은 data augmentation으로 전처리하여 2배로 늘림 → 총 36,129개 이미지
(2) Model architecture
Pre-training을 어떤 데이터셋을 가지고 진행하는지가 GSV를 활용한 추론 결과에 영향을 미친다. 예를 들면 AlexNet에 ImageNet으로 pre-train 시킨 것보다 Places로 pre-train 시킨 게 안전예측 성능이 높게 나오는 식이다(ImageNet: 알고리즘 테스트나 object detection and localization 태스크에 적합, Places: 장면scene 인식에 적합 등). 최근 연구결과를 바탕으로 VGG16 + Places365를 채택했다.
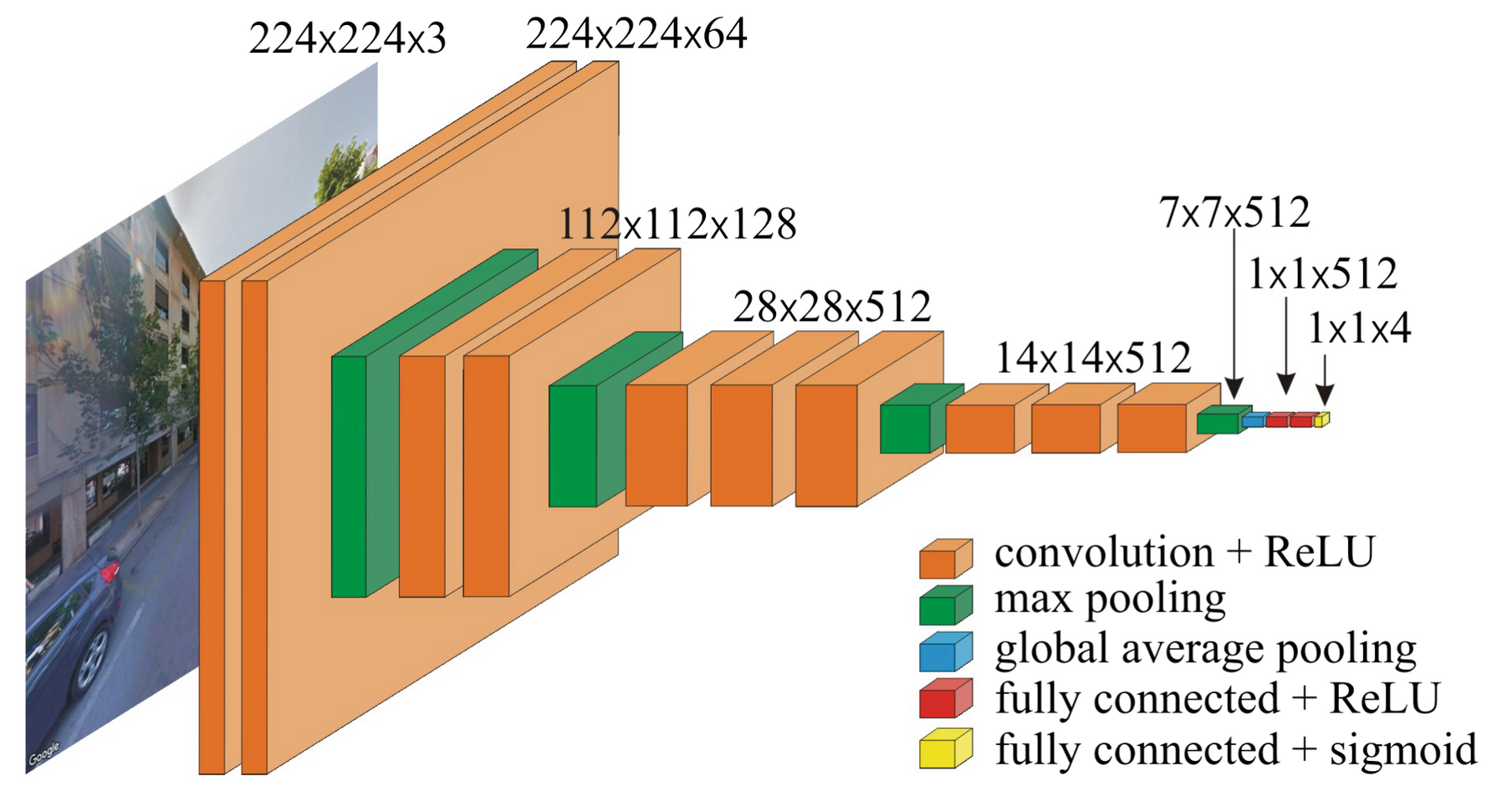
- CNN Transfer learning: Pre-trained deep VGG16 with Places365 + fine-tuning with Google Street View images)
- VGG16 그대로 사용. 13번째 layer로 나온 feature는 7 x 7 x 512이고 → global max-pooling으로 1 x 1 x 512 dimension reduction → FC + ReLU (512 dim) → FC + Sigmoid(512 dim)로 target vector 인코딩 (4 dim)
- Generalization of ordinal perceptron learning approach: 5개 카테고리 점수로 결과가 분류되므로, target vector 로 표현됨. 차원이 해당 카테고리 이상의 카테고리에 속하는지를 나타냄. $𝑜_1$에서 시작하여, 해당 노드의 값이 임계값 보다 작은지 확인하고, 현재 노드의 출력이 임계값 0.5보다 작을 때 중지
(3) Implementation
Loss: MSE , optimizer: adadelta(Keras module)
Validation set에서 loss 변동이 10 epoch 이상 없으면 중단
요약 - Pre-trained VGG16 with Places365, fine-tuning with GSV. Dataset 라벨링은 평가자들이 1점부터 5점까지 순위를 매기는 방식. VGG16 + 마지막 vector encoding으로 도출한 점수 결과가 인간이 라벨링한 것과 일치하는지 확인.
3. Result

Accuracy: 78%(SOTA 비교해서 괜찮다고 함)
MSE: 0.25(MSE 값이 다른 모델이나 기준(benchmark)과 비교되지 않아 좋은 성능을 나타내는지, 아니면 개선이 필요한 수준인지 명확히 알 수 없음)
limitations: 클래스마다 정확도가 다르게 나옴. (1) 데이터셋 클래스 불균형 (2) 인간의 판단으로 인한 오류 (3) 충분치 않은 데이터셋
요약 - 78% accuracy, 99% of correct or 1-class-off predictions, mean square error 0.25
4. Example case-study
Data: 59,293 Google Street View photos of city of Cagliari, Italy
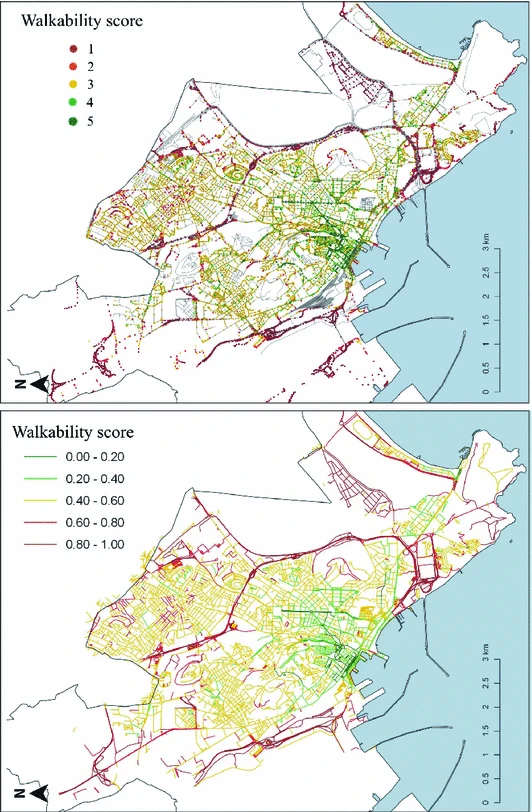
그래프의 edge 점수는 edge에 포함된 score의 average
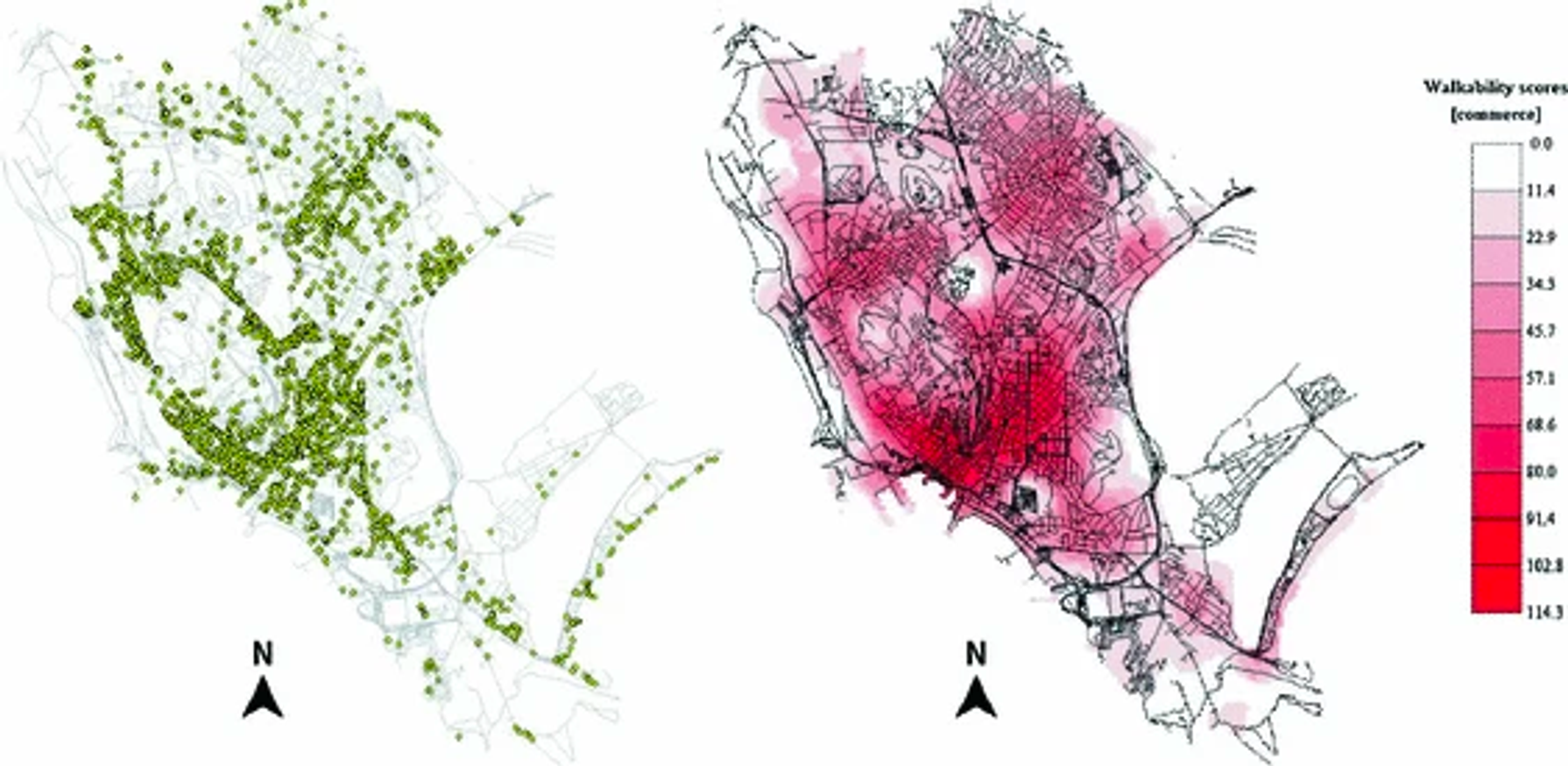
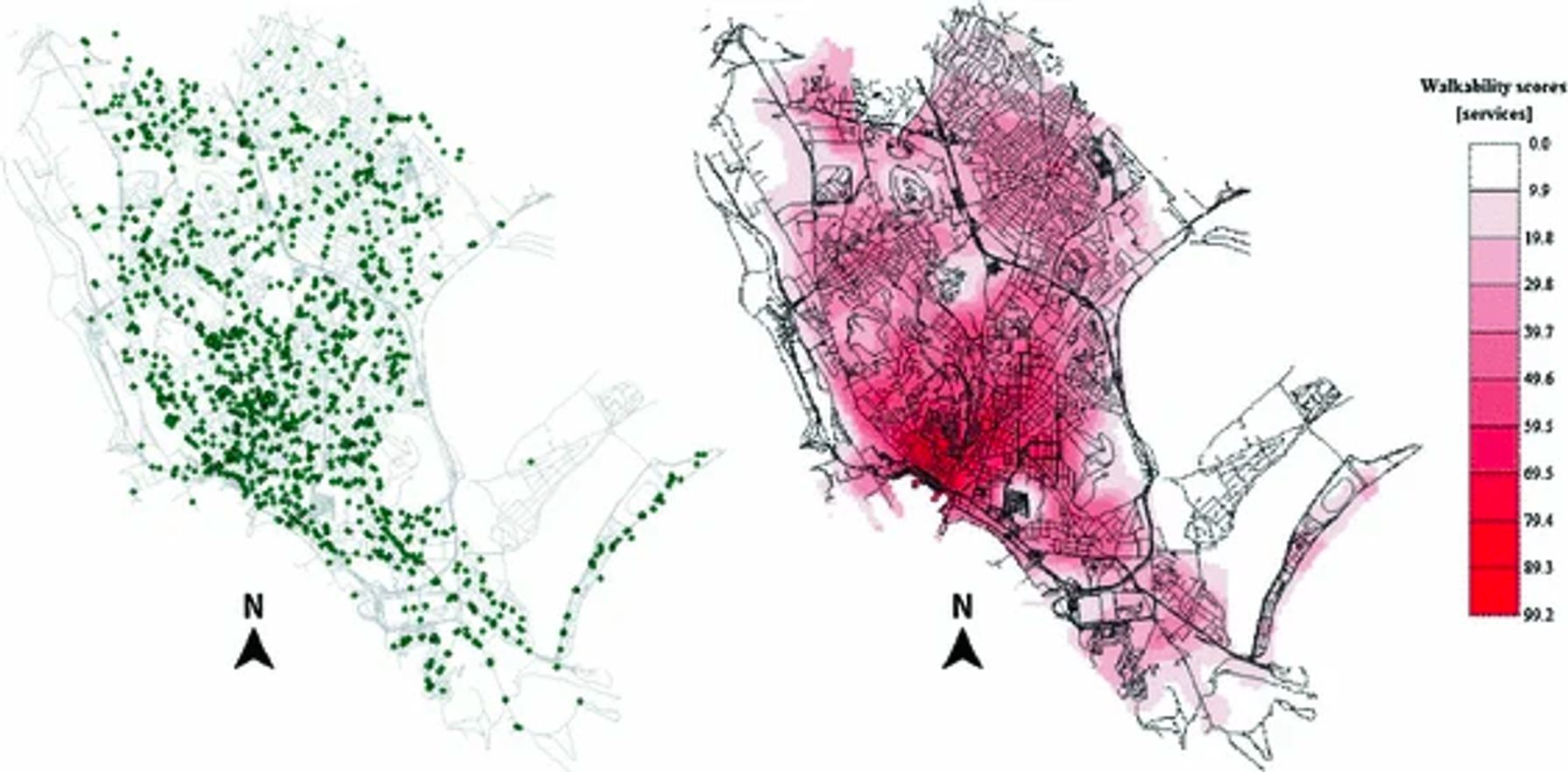
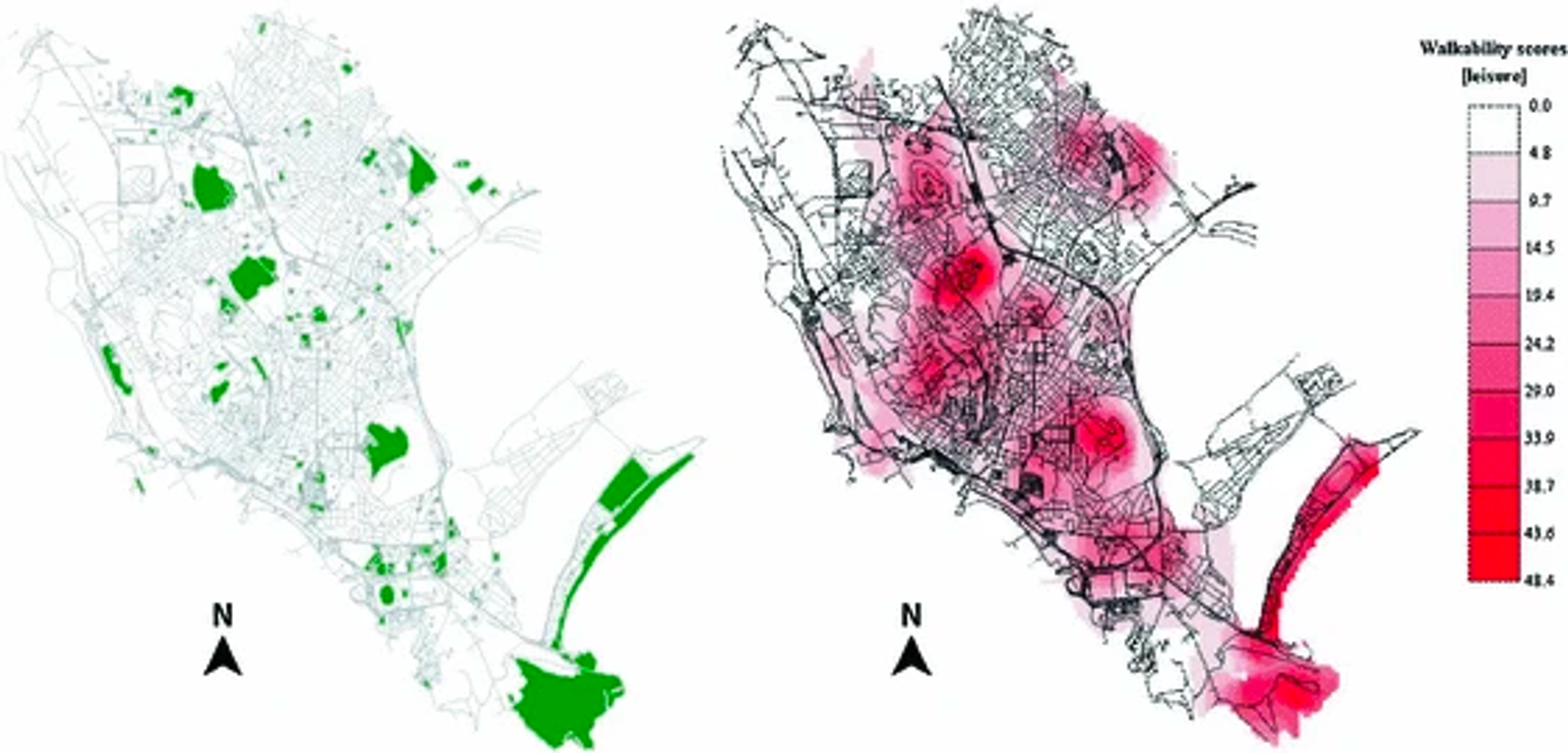
Walkability Explorer 소프트웨어: 이 연구에서는 도로 네트워크의 각 노드에 Walkability Score를 할당하는 Walkability Explorer 소프트웨어를 사용함. 이건 CAWS를 계산하는 데 사용됨. CAWS는 Walkability Explorer 상에서 (1) 활동별 목적지(Google 장소에서 가능한 목적지/관심 지점의 데이터를 약 2,500개 수집하고, 상업, 서비스, 레저와 여가 활동 등 세 카테고리로 분류), (2) 거리(거리 네트워크 그래프), (3) 보행자 경로의 품질(CNN으로 분류된 목적지까지의 walkability 값), 이렇게 계산되어 각 노드에 assign 된다.
이를 통해 해당 지역에서 보행 가능성이 어떻게 분포되어 있는지, 그리고 특정 장소에서 어디로 걸을 수 있는지 등의 정보를 제공하며, 이를 통해 도시의 보행 환경을 개선하는 데 도움을 줄 수 있다
요약 - Walkability Explorer 소프트웨어를 통해 시설 타입별 목적지, walkability score, 거리 네트워크 그래프를 가지고 CAWS를 계산하여 지도에 표현했다.
5. Conclusion
저자는 도시 공간의 거리 수준 이미지에 기계 학습 기술을 적용하여, 인지된 도시 적합성을 자동으로 대량 평가하는 방법론을 제시함
인간의 인지된 보행 가능성 평가와 테스트 세트에서 기계 학습 알고리즘이 예측한 것 사이에 주목할만한 정확도와 일치성을 얻을 수 있었음(78% 정확, 99% 정확 또는 1-클래스 오프, 평균 제곱 오차 0.25). 이러한 정확도 수준은 문헌에 보고된 이전의 유사한 응용 분야에서 얻은 것과 comparable or surpass
큰 도시 지역에서의 대규모 응용 프로그램을 위한 초석이 될 것, 여러 지역의 많은 도시들간의 보행 가능성을 대량으로 평가하고 비교할 수 있다는 것을 보여줌
6. Comment
- 도시에 대한 사전 지식이 없는 상태에서 해당 연구 결과를 보는 걸로 이 연구의 결과가 믿을 수 있는지 알기 어려움
- 지도에 보행 가능성 점수를 맵핑하는 것에서 더 나아가 실제 보행 환경 개선이 필요한 것으로 나타난 지역의 샘플을 보여주면 좋았을 것 같음
- 사전에 교육된 평가자라고 하더라도 인간이 직접 매긴 1~5점 점수를 그대로 활용하여 학습 데이터셋을 만드는 것은 신뢰하기 어려워 보임. 성별 및 인종, 거주민 여부, 이민자 여부 등 평가자와 인식하는 정도가 다를 수 있음
- Pre-trained VGG16 모델을 실험에 이용한 점. 지금 다시 모델을 선택한다면...
- GSV를 가지고 연구할 때, 어떤 데이터셋을 가지고 pre-training 할지 고르게 된 배경을 알 수 있었음



